Orca Tipps
Folgende Seite präsentiert einige nützliche Tipps und Tricks für die Arbeit mit dem Quantenchemie-Paket Orca.
Zur Struktur eines Inputfiles
! HF def2-TZVP
%scf
convergence tight
end
* xyz 0 1
C 0.0 0.0 0.0
O 0.0 0.0 1.13
*
In einem Orca-Input File werden die Keywords mit einem ! eingeleitet. Dort kann man dann beispielsweise die Methode, den Basisatz und verschiedene Algorithmen wie Geometrieoptimierung oder Frequenzberechnung angeben.
Mittels % und end können spezifische Optionen für verschiedene Module angebeben werden. So wird im obigen Biespiel die SCF-Konvergenz auf “tight” gesetzt. Man kann in einem Inputfile Kommentare mit dem # Zeichen einfügen.
# Dies ist ein Kommentar im Inputfile
Man hat die Möglichkeit folgende Blöcke mit % zu verwenden:
%scf- Optionen für das SCF-Modul%geom- Optionen für Geometrieoptimierung%freq- Optionen für Frequenzberechnung%pal- Optionen für Multiprocessing%basis- Definition von Basissätzen
Überblick über die wichtigsten Methoden und und Runtypes
Folgende Aufzählung gibt einen Überblick über die wichtigsten Keywords welche mit ! angegeben werden können:
HF- Hartree-Fock MethodeDFT- DichtefunktionaltheorieMP2- Møller-Plesset Störungstheorie zweiter OrdnungCCSD- Coupled-Cluster mit Einzel- und DoppelanregungenCCSD(T)- Coupled-Cluster mit Singles, Doubles und perturbativen TriplesOPT- Geometrieoptimierung mit redundant internal CoordinatesFREQ- FrequenzberechnungNUMFREQ- Numerische FrequenzberechnungSP- Single-Point Energie Berechnung
Koordinaten Input in Orca
Koordinaten können entweder direkt im Input-File angegeben werden oder man lädt sie aus einer externen Datei. Man hat sowohl die Möglichkeit kartesische Koordinaten als auch Z-matrizen zu verwenden.
Die Kartesichen Koordinaten werden im * xyz Block angegeben. Dieser Block hat folgende Struktur:
* xyz Charge Multiplicity
Atom1 x1 y1 z1
Atom2 x2 y2 z2
...
*
Note Man gibt hier immer die Multiplizität des Systems an welche durch $2S+1$ definiert ist, mit $S$ als Gesamtspin des Systems. Möchte man beispielsweise $O_2$ im Triplett-Zustand berechnen (was dem Grundzustand entspricht) so gibt man
* xyz 0 3an.
Multiprocessing in Orca
In Orca kann man mehrere Prozessoren für eine Berechnung verwenden um die Rechenzeit zu verkürzen. Dies basiert auf OpenMPI welches ein Message Passing Interface ist und Routinen für die parallele Programmierung im High-Performance-Computing (HPC) bereitstellt. In Orca selbst kann man durch die Angabe von %pal im Inputfile die Anzahl der Prozessoren definieren.
!HF DEF2-SVP
%PAL NPROCS 10 END
Mit dieser Option muss man für die Ausführung von Orca den ganzen Pfad zum Programm angeben. Den File-Path bekommt man in Linux durch den Befehl which orca. Das Programm kann dann wie folgt gestartet werden:
$ ./full/path/to/orca input.inp > output.out
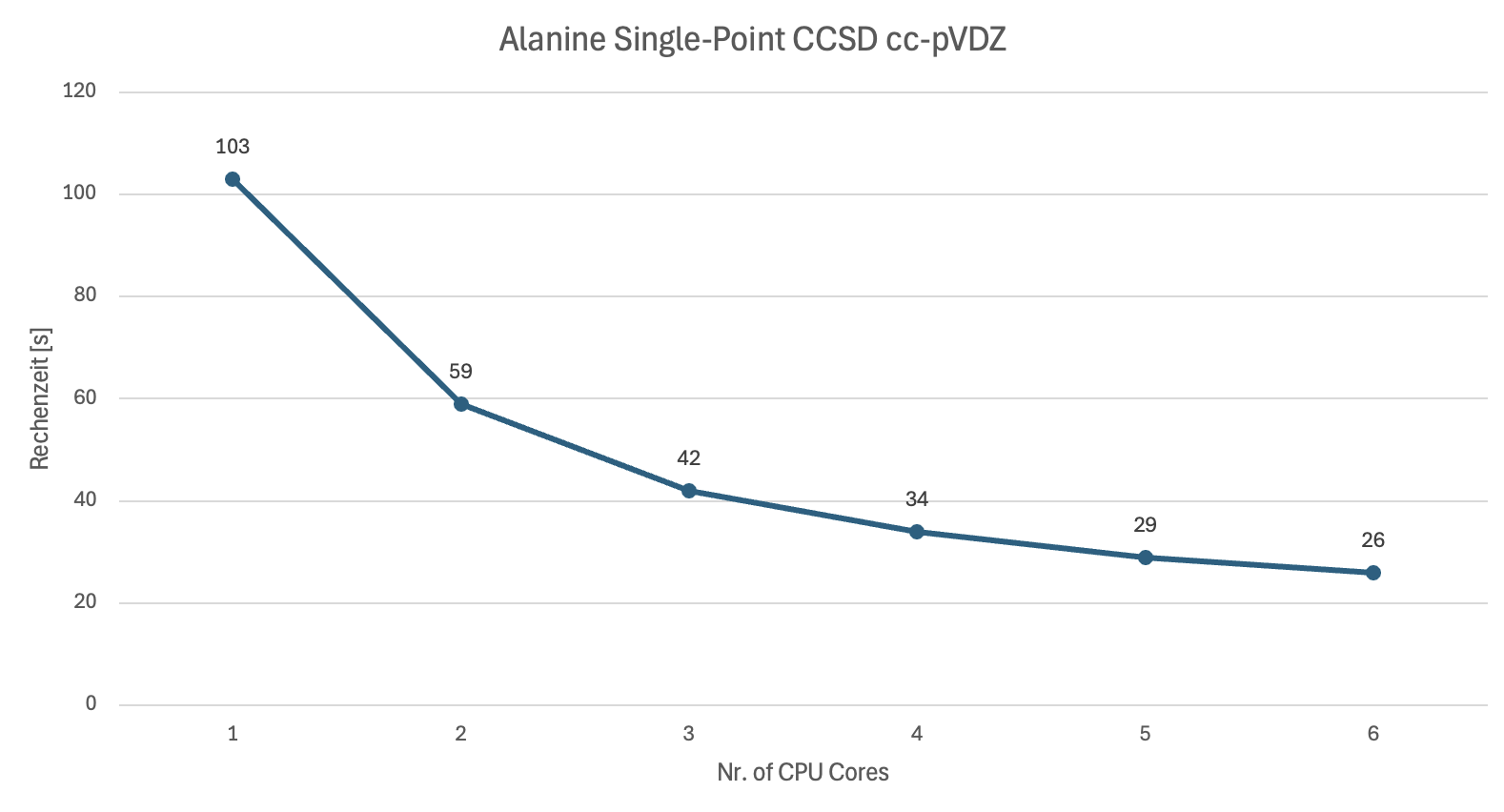
Grundsätzlich sind alle Hauptmodule in Orca parallelisiert. Je nach Methode und Basissatz kann die Skalierung jedoch varrieren. Folgende Abbildung zeigt beispielsweise die Skalierung der Rechenzeit für eine Single-Point Energie Berechnung der Aminosäure Alanin mit der Coupled-Cluster Methode CCSD und dem cc-pVDZ Basissatz.
Global Memory Usage
Einige Module in Orca wie beispielsweise die korrelierten Methoden brauchen eine große Menge an Scratch Array. Dies wird im Rahmen des Praktikums sicherlich keine Probleme bereiten, man kann jedoch global allen Modulen eine bestimmte Menge an Scratch Memory zuweisen. Dieses Limit wird dann für jeden Prozessor gesetzt:
%MaxCore 4000
Dies setzt zum Beispiel ein Limit von 4000 MB pro Prozessor.